昨天帶各位實作了GAN的應用,實際帶各位操作一次不知道是否有加深各位對GAN的印象了。希望各位能藉由實作更理解GAN的原理以及訓練方式。不過如前幾天所說,GAN在訓練其不穩定性是最大的問題,今天要帶各位分析一下昨天的訓練,順便介紹一下GAN在訓練中常見的訓練問題。
昨天有將生成器與判別器的損失存成npy檔案了 (在save_data()那邊),這是Numpy Array的格式,儲存後可以於之後使用np.load(file_name)來讀取之前儲存的陣列資料。
注意路徑要根據電腦中專案的位置去更改喔!
import numpy as np
import matplotlib.pyplot as plt
#匯入昨天儲存的損失資料
discriminator_loss = np.load('./result/discriminator_loss.npy') #路徑請根據實際位置更改
generator_loss = np.load('./result/generator_loss.npy') #路徑請根據實際位置更改
#將圖片畫出來
plt.title('Training Process of GAN')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.plot(discriminator_loss, label='Discriminator loss')
plt.plot(generator_loss, label='Generator loss')
plt.legend(loc='best')
plt.grid(True)
plt.show()
執行程式碼以後可以看到損失圖如下,還是要提醒一下因為深度學習訓練時跟機率有關,所以每一次跑出來的結果都會不一樣,若你發現圖片跟我不同,或者跑了兩次程式碼出來的結果不同都是正常的。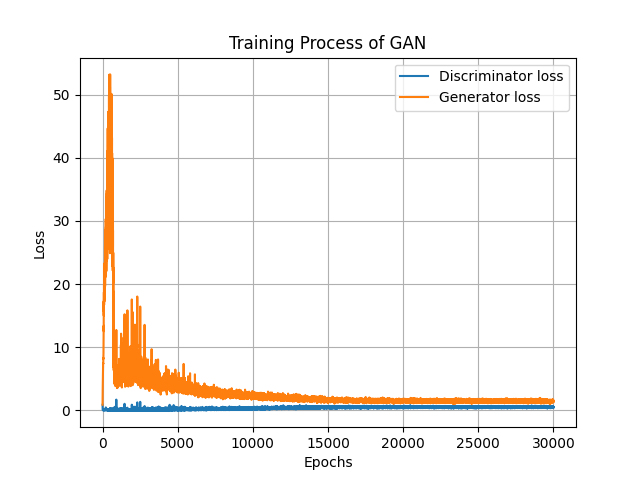
可以發現生成器訓練初期的損失震盪幅度較大,值也很大,導致看不清楚詳細的損失變化,那這時候我通常會取對數也就是利用*log(x+1)*的公式將數據的最大最小值壓縮起來,至於要使用何種公式來讓數據更清楚也並沒有硬性規定,各位可以使用許多手段來讓資料變得易於閱讀。題外話,使用這個方式可以使值比較貼近常態分佈。log(x+1)也可以使用np.log1p(x)來計算。經過log計算的損失變成這樣:
discriminator_loss = np.log1p(discriminator_loss)
generator_loss = np.log1p(generator_loss)
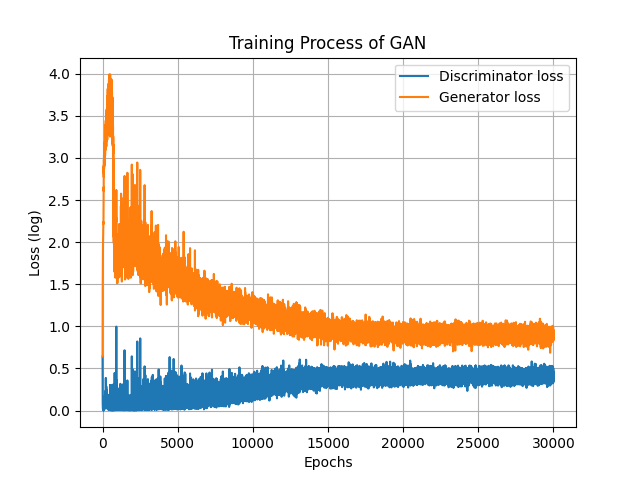
可以比較清楚的看到生成器與判別器損失的變化了,由圖可知,對抗式學習的損失變化通常都會呈現震盪不穩定的樣子,不過到最後也會發現損失逐漸收斂,這代表生成對抗網路訓練的已經達到納許均衡 (Nash equilibrium)了。此時增加訓練次數基本上也無濟於事了。但是,圖片生成的質量與模型收斂卻不太容易從損失圖看出來,就算訓練達到穩定了,也有可能生出來的圖一樣差,所以還是要關注一下訓練過程產生的圖片!這次訓練是在約15000次訓練時達到納許均衡的,所以可以來看看生成器在每一段訓練後儲存的圖片。
Epoch=0,完全沒有訓練當然是雜訊。
Epoch=400,開始有在慢慢在"演化"了 (雖然還是看不太出來)。
Epoch=1600,生成的圖長的很類似,都長得像0。
Epoch=5000,生成的圖片變得都長得像1,直到訓練次數到達10000都是差不多的結果。
Epoch=15000,開始會生成別的數字圖片了!
Epoch=29800,生成結果還算令人滿意,但偶爾還是會有一些數字較難以辨識。
以上就是昨天的程式在訓練過程中的種種變化,的確看的出來在過了10000次訓練後生成器能力開始提升,而且訓練最終達到了一個平衡,再之後訓練的結果就比較能夠看出一個所以然了。最後我將訓練的過程轉換成GIF了,給各位看看訓練的過程吧。
前幾天常說到GAN在訓練時常常會出現問題,這些問題在比較複雜的生成任務才會比較容易出現。常遇到的問題有:梯度消失、梯度爆炸、訓練失衡、模式崩潰等,這些常見問題會對訓練造成甚麼影響,接著就來介紹一下吧!
基本上不同模型中可能會有專屬的問題要解決,所以今天只列出最常見的問題。
GAN的訓練常常會遇到訓練失衡的問題,原因不外乎就是生成器太強或者判別器太強。當生成器太強時,生成器胡亂生成一批圖片,判別器也無法分辨出來圖片的真假,但這不代表生成器的圖片很優秀,只是判別器太弱根本沒辦法分辨圖片;相反的判別器太強就會導致生成器無論如何生成判別器都分辨得出來,這導致生成器可能會無法繼續訓練而直接擺爛,此時生成器就會生成許多莫名其妙的東西。
如何解決:訓練GAN時,參數的設定相當重要。例如:
上述原因都會影響到訓練。所以參數的調整對訓練來說非常重要,如何使用好的參數也是在訓練GAN時需要慢慢調整的!
前幾天的文章有提到到類神經網路優化方式是透過反向傳播,而反向傳播需要使用梯度下降法計算每一層中每一個神經元權重與偏差值的梯度。當神經網路層數太多,導致由後面層計算到前面層的梯度因為經過不斷的使用連鎖律偏微分導致梯度降到幾乎為0甚至因為太小被程式直接計為0,此時就是梯度消失。因為梯度為0所以模型無從得知優化的方向,導致模型無法繼續優化,導致訓練變異常緩慢甚至完全停滯。
如何解決:在訓練GAN時,可以使用一些神經網路層來避免梯度消失。例如:
與梯度消失相反,梯度爆炸是梯度因為隨著神經網路層數計算梯度,而此過程中梯度計算越來越大,此時模型會發散,結果來說也就是完全無法訓練,而且也有可能因為數值太大而導致程式直接噴錯誤。
如何解決:基本上遇到梯度爆炸除了使用ReLU、LeakyReLU、Batch Normalization以外也可以使用梯度裁剪 (Gradient Clipping)來避免梯度爆炸,梯度裁剪是指在反向傳播計算梯度時,設定一個閥值,若梯度高於閥值則直接將梯度設定為該閥值。或者使用**權重正規化 (**Weight Regularization),通過對網路權重做正規化來限制過度擬合,也可以減少權重的大小,進一步避免梯度爆炸。
模式崩潰是一種在GAN訓練中常見的問題,它會導致生成器無法生成多樣化的樣本,而只能生成重複或無意義的樣本。這可能是因為生成器和判別器之間的訓練不平衡,使得生成器陷入一種局部最優的狀態,而不再學習新的特徵。
如何解決:這個問題主要也是因為生成器與判別器訓練失衡所引起的,解決辦法與上面提到的訓練失衡差不多。除此之外也可以使用Wasserstein GAN等模型來避免模式崩潰。
今天帶各位回顧昨天的訓練成果、以及向各位介紹了一些GAN訓練中最常見的問題,不過因應任務類型不同,所以有時也會出現一些特定的問題,而這些可能出現的問題會在之後介紹特定模型時與各位詳細介紹!明天會向各位介紹第二個GAN模型,此模型使用卷積神經網路 (Convolutional Neural Network, CNN)為主軸,因為是圖像生成任務,所以還是該使用以專門處理圖像的CNN吧XD
常常會遇到模型訓練與該模型原始論文的結果不同,或者遇到論文中沒提到的問題,請保持耐心慢慢研究問題所在~

